

Simple Guide to Maturing Responsible AI
AI ontwikkelt zich razendsnel, maar roept tegelijkertijd vragen op rondom governance, risico’s en vertrouwen. Voor veel organisaties is het onduidelijk waar te beginnen en hoe AI op een...


Een Machine Learning-algoritme, ook wel model genoemd, is een wiskundige uitdrukking die gegevens representeert in de context van een probleem, vaak een zakelijk probleem. Het doel is om van data naar inzicht te gaan. Als een online retailer bijvoorbeeld wil anticiperen op verkopen voor het volgende kwartaal, kan hij een Machine Learning-algoritme gebruiken dat die verkopen voorspelt op basis van eerdere verkopen en andere relevante gegevens.
Machine Learning is een hot topic en er worden voortdurend nieuwe methodologieën ontwikkeld. De snelheid en complexiteit van het vakgebied maakt het zelfs voor experts moeilijk om nieuwe technieken bij te houden, laat staan voor beginners.
Laten we eens kijken naar 5 verschillende Machine learning algoritmen, inclusief eenvoudige beschrijvingen, visualisaties en voorbeelden, met als doel de “magie van Machine Learning te ontrafelen, en een basis inzicht te bieden voor degenen die nieuw zijn in de wereld van Data Science.
Lineaire regressie is waarschijnlijk het meest bekende ML-algoritme. Het vindt een lijn die het beste past bij een verspreide datapunten in een grafiek. Het probeert het verband tussen onafhankelijke factoren (de x-waarden) en een numeriek resultaat (de y-waarden) weer te geven door de vergelijking van een lijn aan die gegevens te koppelen. Deze lijn zou dan kunnen worden gebruikt om te anticiperen op toekomstige waarden!
De meest bekende procedure voor dit algoritme is de zogenaamde kleinste kwadratenmethode. Deze strategie berekent de best passende lijn met als einddoel dat de verticale afstand van elk datapunt van de lijn het kleinst is.
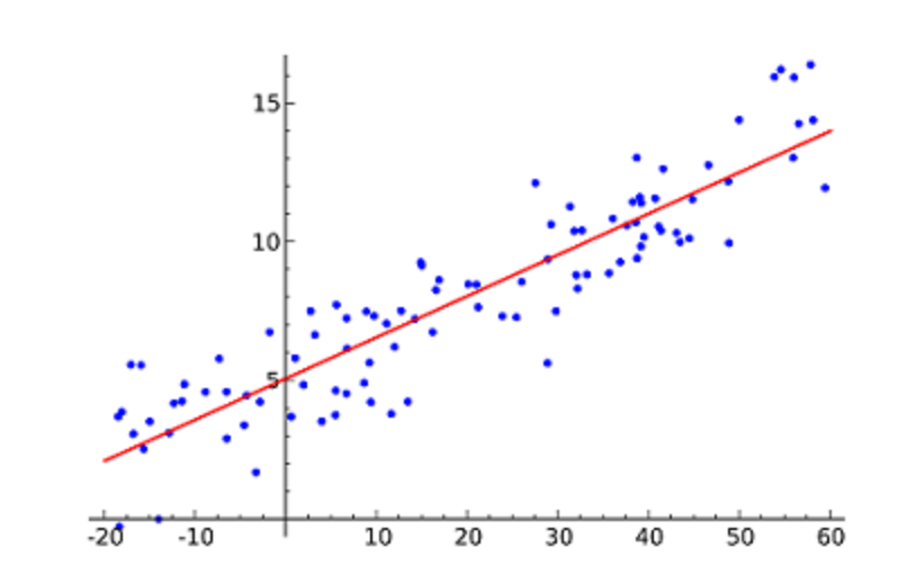
Voorbeeld van een eenvoudige lineaire regressie, die één vrije variabele (x-as) en een afhankelijke variabele (y-as) heeft
Logistische regressie lijkt enigszins op lineaire regressie, maar wordt gebruikt wanneer het resultaat binair is (bijvoorbeeld op het moment dat het resultaat slechts twee mogelijke waarden kan hebben). Met logistische regressie analyses kun je een voorspellend model maken om de kans op een positieve uitkomst van een categorisch afhankelijke variabele te voorspellen. Dit kan met één of meerdere onafhankelijke variabelen.
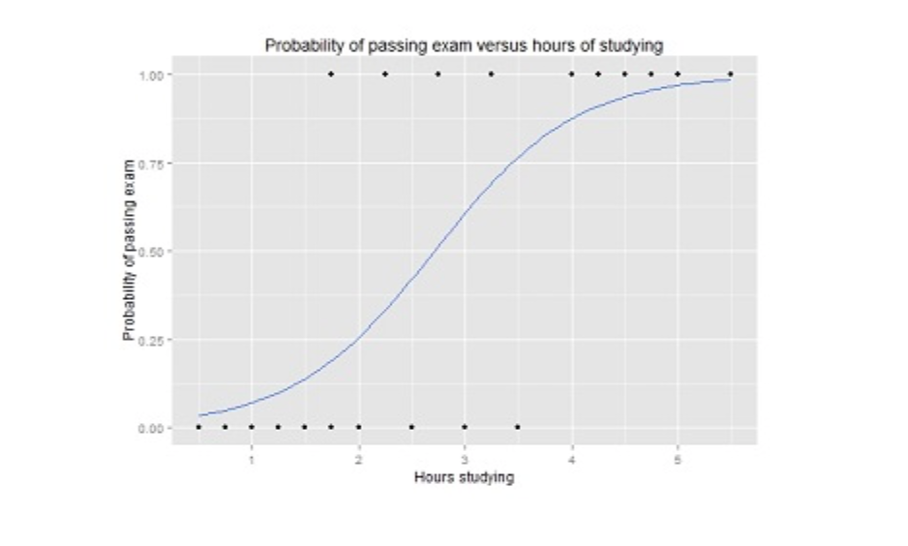
Diagram van een logistieke regressiecurve die de waarschijnlijkheid van het slagen voor een test in relatie tot het aantal uren studie aantoont.
De support vector machine is algoritme dat gebruikt wordt voor het classificeren van binaire gegevens. Het algoritme verdeelt de ingevoerde dataset in 2 klassen, aan de hand van vooraf geselecteerde kenmerken. Voordat dit onderscheid gemaakt kan worden moet het bijbehorende model getraind worden met historische data. Support vector machines worden o.a. gebruikt bij gezichtsherkenning en genetisch onderzoek.
Data Scientists gebruiken dit algoritme als ze veel ongelabelde gegevens hebben (alle informatie zonder gedefinieerde groepen of categorieën.) K betekent dat clustering tot doel heeft om gegevens voor verschillende groepen te zoeken. Het algoritme met de eerste schattingen van de central K centroid. Deze kunnen willekeurig worden geselecteerd of willekeurig worden gegenereerd uit de dataset. Het algoritme past vervolgens iteratieve verfijningstechnieken toe op basis van gelijkenis kenmerken totdat er resultaten worden verkregen en er clusters worden gedefinieerd. Zodra het algoritme zijn proces heeft voltooid en de groep is gedefinieerd, kunt je eenvoudig nieuwe gegevens aan de betreffende groep toewijzen.
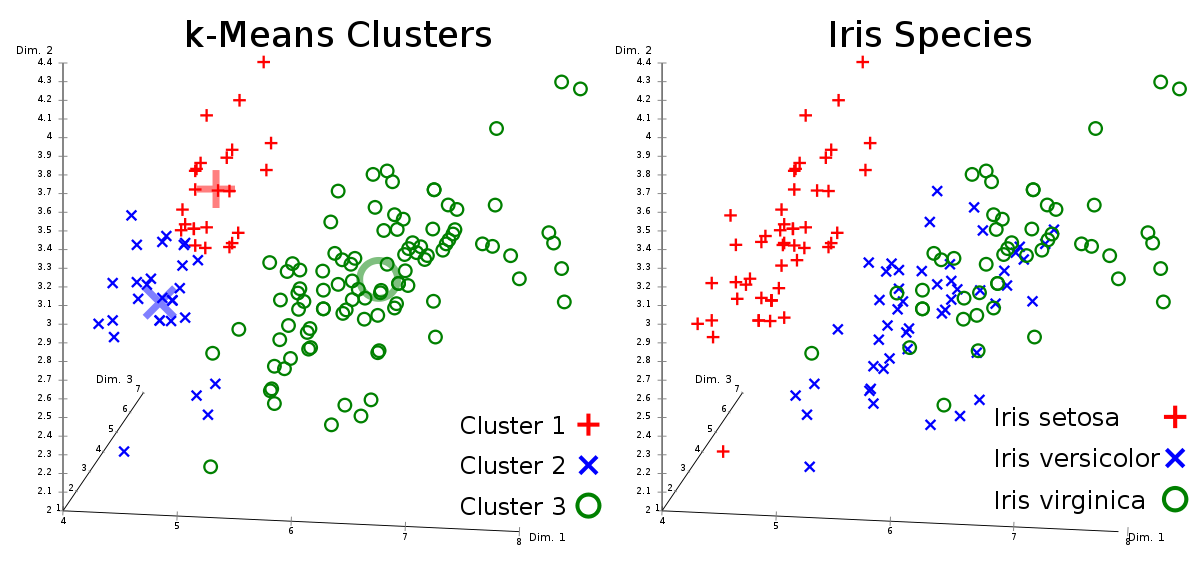
Voorbeeld van K means clustering toegepast op een dataset met verschillende soorten irissen (bloemen).
Een toepassingsvoorbeeld van dit algoritme is bijvoorbeeld het segmenteren van website bezoekers op basis van aankoophistorie, of de detectie van verschillende activiteiten in bewegingssensoren.
Recurrent neural networks worden gebruikt voor de interpretatie van semi- of ongestructureerde data. Ze kunnen bijvoorbeeld worden ingezet voor het maken van vertalingen of spraakherkenning. Door deze technologie kunnen spraakassistenten de stem en het accent van hun ‘eigenaar’ herkennen. Hierdoor zullen ze steeds beter reageren op de commando’s, en kan de gebruiker steeds natuurlijker gaan spreken tegen het apparaat.
Een belangrijk element bij RNN’s is het geheugen van het systeem. Dit geheugen slaat vergaarde informatie op, en past de input en output erop aan. In het voorbeeld van de spraak assistent zien we bijvoorbeeld dat deze na een tijdje ook regionale bewoordingen begrijpt en zelfs gebruikt. Een ander voorbeeld zijn de suggesties die verschijnen als de gebruiker een bericht typt op een mobiele telefoon. Op basis van voorgaande berichten die met de telefoon geschreven zijn, worden bij het typen van een woord meteen de volgende woorden of zelfs zinnen voorgesteld.
Wil je meer weten over de waarde die Data Science je bedrijf kan bieden? Download dan de klantcase, en lees hoe Agentschap Telecom Data Science technieken inzet om de hoge directe herstelkosten van graafschade te reduceren.

