Klantencase Agentschap Telecom
Agentschap Telecom stond voor de uitdaging om graafschades aan ondergrondse kabels en leidingen te verminderen — een probleem met grote maatschappelijke en economische impact. Door data uit...

-2.png)
Data Science is een divers werkveld waarin mensen met zeer uiteenlopende achtergronden werken in verschillende branches. De hype is rondom Data Science brengt ook veel mythes met zich mee.
In dit blog ontkrachten we enkele van de meest voorkomende mythes over Data Science.
Dit is de meest voorkomende Data Science mythe. Het zal zeker zo zijn dat AI veel van de vervelende en repetitieve taken op het vlak van Data Science zal uitvoeren, zoals bijvoorbeeld het voorbereiden en opschonen van gegevens. Er zal echter altijd een Data Scientist nodig zijn om de geavanceerde bewerkingen uit te voeren, en de machine te vertellen wat er moet gebeuren.
Er is een tendens om Data Science zoveel mogelijk te automatiseren. Mensen bouwen steeds geavanceerdere algoritmen met de intentie om de behoefte aan een ‘dedicated’ Data Scientist te elimineren. Het is echter zeer onwaarschijnlijk dat dit zal gebeuren, aangezien zelfs de meest geavanceerde AI-systemen werken met hetgeen we hen vertellen om mee te werken, en altijd menselijke begeleiding nodig hebben.
De AI- of machine learning-systemen kunnen niet beoordelen wat goed is voor de zakelijke problemen die geadresseerd worden, en welke domeinkennis hen zal helpen. Ze weten ook niet wat de trends en voorspellingen betekenen in de context van de ‘echte’ wereld, en op welke wijze het bedrijf als geheel hiervan kan profiteren. Daarom is de Data Scientist een blijvertje, en is de vraag naar mensen met deze specifieke vaardigheden is ongekend hoog.
Hoe graag ik ook zou willen dat dit waar was, dit is gewoon weer een veelvoorkomende dat science mythe. Het bouwen van Machine Learning-modellen is een van de kleine stukjes van de (Big) Data Science -pijplijn, die bestaat uit dataverzameling, data-opschoning, datavoorbereiding, data “wrangling”, visualisatie, analyse, modelimplementatie en nog veel meer zaken.
Over het algemeen neemt het bouwen van alle Machine Learning & Deep Learning-modellen ongeveer 15-25% van de totale tijd in de Data Science-pijplijn in beslag. Meer dan 50-60% van de tijd in de Data Science-pijplijn gaat naar het opschonen van gegevens, en het voorbereiden en verzamelen daarvan.
Dit is een grote mythe in de Data Science wereld. Het hebben van bedrijfs- of domeinkennis is van cruciaal belang in Data Science. Het is juist datgene wat een ervaren Data Scientist onderscheidt van iemand die net aan zijn of haar carrière is begonnen. In elke stap in de Data Science-pijplijn is domeinkennis noodzakelijk voor de juiste data visualisatie, -analyse en “featurisation”. Daarnaast zorgt domeinkennis voor het optimaal begrijpen van de zakelijke doelstellingen.
Hoewel dit een vereiste is, gaat het beheersen van Data Science niet alleen over het leren van de mooie tools en talen. Je bent niet alleen maar een programmeur, hoewel de tools en talen je wel op vele wijzen helpen.
Data Science vereist analytisch en zakelijk inzicht, samen met het begrip van de toepassingen van statistiek, Machine Learning en AI voor het oplossen van zakelijke problemen.
Een Data Scientist moet goede probleemoplossende vaardigheden hebben, en weten waar en wanneer hij of zij een tool of een algoritme moet toepassen voor de gegeven bedrijfsdoelstelling. Ook moet men het belangrijke vermogen hebben om resultaten op een eenvoudige en intuïtieve manier aan de belanghebbenden te communiceren.
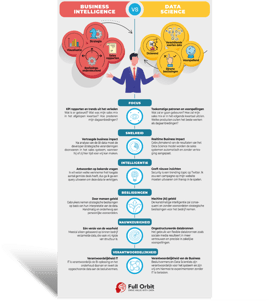
Wil je meer weten over de waarde die Data Science je bedrijf kan bieden, en wat het verschil is ten opzichte van standaard Business Intelligence oplossingen, download dan onderstaande Infographic.